MULTIGRID
Multigrid Framework
We saw the rate of convergence for iterative methods depends upon the iteration matrix. Point iterative methods like Jacobi and Gauss-Seidel methods have large eigenvalue and hence the slow convergence. As the grid becomes finer, the maximum eigenvalue of the iteration matrix becomes close to 1. Therefore, for very high-resolution simulation, these iterative methods are not feasible due to the large computational time required for residuals to go below some specified tolerance.
The multigrid framework is one of the most efficient iterative algorithm to solve the linear system of equations arising due to the discretization of the Poisson equation. The multigrid framework works on the principle that low wavenumber errors on fine grid behave like a high wavenumber error on a coarse grid. In the multigrid framework, we restrict the residuals on the fine grid to the coarser grid. The restricted residual is then relaxed to resolve the low wavenumber errors and the correction to the solution is prolongated back to the fine grid. We can use any of the iterative methods like Jacobi, Gauss-Seidel method for relaxation. The algorithm can be implemented recursively on the hierarchy of grids to get faster convergence.
Basic Iterative Methods
We now consider how model problems might be treated using conventional iterative or relaxation methods. We first establish the notation for this and all remaining chapters. Let
denote a system of linear equations. We always use \(\mathbf{u}\) to denote the exact solution of this system and \(\mathbf{v}\) to denote an approximation to the exact solution, perhaps generated by some iterative method. Bold symbols, such as \(\mathbf{u}\) and \(\mathbf{v}\), represent vectors, while the \(j\text{th}\) components of these vectors are denoted by \({u}_{j}\) and \({v}_{j}\). In later chapters, we need to associate \(\mathbf{u}\) and \(\mathbf{v}\) with a particular grid, say \({\Omega}^{h}\). In this case, the notation \({u}^{h}\) and \({v}^{h}\) is used.
Suppose that the system \(A\mathbf{u}=\mathbf{f}\) has a unique solution and that \(\mathbf{v}\) is a computed approximation to \(\mathbf{u}\). There are two important measures of \(\mathbf{v}\) as an approximation to \(\mathbf{u}\). One is the error (or algebraic error) and is given simply by
The error is also a vector and its magnitude may be measured by any of the standard vector norms. The most commonly used norms for this purpose are the maximum (or infinity) norm and the Euclidean or 2-norm, defined, respectively, by
Unfortunately, the error is just as inaccessible as the exact solution itself. However, a computable measure of how well \(\mathbf{v}\) approximates \(\mathbf{u}\) is the residual, given by
The residual is simply the amount by which the approximation \(\mathbf{v}\) fails to satisfy the original problem \(A\mathbf{u}=\mathbf{f}\). It is also a vector and its size may be measured by the same norm used for the error. By the uniqueness of the solution, \(\mathbf{r}=0\) if and only if \(\mathbf{e}=0\). However, it may not be true that when \(\mathbf{r}\) is small in norm, \(\mathbf{e}\) is also small in norm.
Residuals and Errors.
A residual may be defined for any numerical approximation and, in many cases, a small residual does not necessarily imply a small error. This is certainly true for systems of linear equations, as shown by the following two problems:
and
Both systems have the exact solution \(\mathbf{u}=(1,2)^{T}\). Suppose we have computed the approximation \(\mathbf{v}=(1.95, 3)^{T}\). The error in this approximation is \(\mathbf{e}=(-0.95, -1)^{T}\), for which \(\|\mathbf{e}\|_{2}=1.379\). The norm of the residual in \(\mathbf{v}\) for the first system is \(\|\mathbf{r}_{1}\|_{2}=0.071\), while the residual norm for the second system is \(\|\mathbf{r}_{2}\|_{2}=1.851\). Clearly, the relatively small residual for the first system does not reflect the rather large error.
Remembering that \(A\mathbf{u}=\mathbf{f}\) and using the definitions of \(\mathbf{r}\) and \(\mathbf{e}\), we can derive an extremely important relationship between the error and the residual:
We call this relationship the residual equation. It says that the error satisfies the same set of equations as the unknown \(\mathbf{u}\) when \(\mathbf{f}\) is replaced by the residual \(\mathbf{r}\). The residual equation plays a vital role in multigrid methods and it is used repeatedly throughout this tutorial.
We can now anticipate, in an imprecise way, how the residual equation can be used to great advantage. Suppose that an approximation \(\mathbf{v}\) has been computed by some method. It is easy to compute the residual \(\mathbf{r}=\mathbf{f}-\mathbf{A}\mathbf{v}\). To improve the approximation \(\mathbf{v}\), we might solve the residual equation for e and then compute a new approximation using the definition of the error
In practice, this method must be applied more carefully than we have indicated. Nevertheless, this idea of residual correction is very important in all that follows.
Model Problems
Multigrid methods were originally applied to simple boundary value problems that arise in many physical applications. For simplicity and for historical reasons, these problems provide a natural introduction to multigrid methods. As an example, consider the two-point boundary value problem that describes the steady-state temperature distribution in a long uniform rod. It is given by the second-order boundary value problem
While this problem can be handled analytically, our present aim is to consider numerical methods. Many such approaches are possible, the simplest of which is a finite difference method. The domain of the problem \(\{x:0\le x\le 1\}\) is partitioned into \(n\) subintervals by introducing the grid points \(x_{j}= jh\), where \(h = 1/n\) is the constant width of the subintervals.
At each of the \(n−1\) interior grid points, the original differential equation is replaced by a second-order finite difference approximation. In making this replacement, we also introduce \(v_{j}\) as an approximation to the exact solution \(u(x_{j})\). This approximate solution may now be represented by a vector \(\mathbf{v}=(v_{1}, . . . , v_{n-1})^{T}\), whose components satisfy the \(n−1\) linear equations
One-dimensional grid on the interval \(0\le x\le 1\). The grid spacing is \(h=\cfrac{1}{n}\) and the jth grid point is \(x_{j} = jh\) for \(0\le j\le n\).
Defining \(\mathbf{f}=(f(x_{1}),\cdots,f(x_{n-1}))^{T}=(f_{1},\cdots,f_{n-1})^{T}\), the vector of right-side values, we may also represent this system of linear equations in matrix form as
or even more compactly as \(A\mathbf{v}=\mathbf{f}\). The matrix \(A\) is \((n-1)\times(n-1)\), tridiagonal,symmetric, and positive definite.
We now turn to relaxation methods for our first model problem with \(\sigma = 0\). Multiplying that equation by \(h^{2}\) for convenience, the discrete problem becomes
One of the simplest schemes is the Jacobi (or simultaneous displacement) method. It is produced by solving the \(j\text{th}\) equation for the \(j\text{th}\) unknown and using the current approximation for the \((j −1)\text{st}\) and \((j+1)\text{st}\) unknowns. Applied to the vector of current approximations, this produces an iteration scheme that may be written in component form as
To keep the notation as simple as possible, the current approximation (or the initial guess on the first iteration) is denoted \(v^{(0)}\), while the new, updated approximation is denoted \(v^{(1)}\). In practice, once all of the \(v^{(1)}\) components have been computed, the procedure is repeated, with \(v^{(1)}\) playing the role of \(v^{(0)}\). These iteration sweeps are continued until (ideally) convergence to the solution is obtained.
It is important to express these relaxation schemes in matrix form, as well as component form. We split the matrix \(A\) in the form
where \(D\) is the diagonal of \(A\), and \(−L\) and \(−U\) are the strictly lower and upper triangular parts of \(A\), respectively. Including the \(h^{2}\) term in the vector \(\mathbf{f}\), then \(A\mathbf{u}=\mathbf{f}\) becomes
Isolating the diagonal terms of \(A\), we have
or
Multiplying by \(D^{-1}\) corresponds exactly to solving the \(j\text{th}\) equation for \(u_{j}\), for \(1 \le j \le n − 1\). If we define the Jacobi iteration matrix by
then the Jacobi method appears in matrix form as
There is a simple but important modification that can be made to the Jacobi iteration. As before, we compute the new Jacobi iterates using
However, \(v_{j}^{*}\) is now only an intermediate value. The new iterate is given by the weighted average
where \(\omega \in \mathbf{R}\) is a weighting factor that may be chosen. This generates an entire family of iterations called the weighted or damped Jacobi method. Notice that \(\omega = 1\) yields the original Jacobi iteration.
In matrix form, the weighted Jacobi method is given by
If we define the weighted Jacobi iteration matrix by
then the method may be expressed as
We should note in passing that the weighted Jacobi iteration can also be written in the form
This says that the new approximation is obtained from the current one by adding an appropriate weighting of the residual.
This is just one example of a stationary linear iteration. This term refers to the fact that the update rule is linear in the unknown \(\mathbf{v}\) and does not change from one iteration to the next. We can say more about such iterations in general. Recalling that \(\mathbf{e} = \mathbf{u} − \mathbf{v}\) and \(A\mathbf{e}=\mathbf{r}\), we have
Identifying \(\mathbf{v}\) with the current approximation \(\mathbf{v}^{(0)}\) and \(\mathbf{u}\) with the new approximation \(\mathbf{v}^{(1)}\), an iteration may be formed by taking
where \(B\) is an approximation to \(A^{-1}\). If \(B\) can be chosen “close” to \(A^{-1}\), then the iteration should be effective.
It is useful to examine this general form of iteration a bit further. Rewriting expression above, we see that
where we have defined the general iteration matrix as \(R = I − BA\). It can also be shown that \(m\) sweeps of this iteration result in
where \(C(\mathbf{f})\) represents a series of operations on \(\mathbf{f}\).
Before analyzing or implementing these methods, we present a few more of the basic iterative schemes. Weighted Jacobi computes all components of the new approximation before using any of them. This requires \(2n\) storage locations for the approximation vector. It also means that new information cannot be used as soon as it is available.
The Gauss–Seidel method incorporates a simple change: components of the new approximation are used as soon as they are computed. This means that components of the approximation vector \(\mathbf{v}\) are overwritten as soon as they are updated. This small change reduces the storage requirement for the approximation vector to only \(n\) locations. The Gauss–Seidel method is also equivalent to successively setting each component of the residual vector to zero and solving for the corresponding component of the solution. When applied to the model problem, this method may be expressed in component form as
where the arrow notation stands for replacement or overwriting.
Once again it is useful to express this method in matrix form. Splitting the matrix \(A\) in the form \(A = D − L − U\), we can now write the original system of equations as
or
This representation corresponds to solving the \(j\text{th}\) equation for \(u_j\) and using new approximations for components \(1, 2, \cdots, j − 1\). Defining the Gauss–Seidel iteration matrix by
we can express the method as
Finally, we look at one important variation on the Gauss–Seidel iteration. For weighted Jacobi, the order in which the components of \(\mathbf{v}\) are updated is immaterial, since components are never overwritten. However, for Gauss–Seidel, the order of updating is significant. Instead of sweeping through the components (equivalently, the grid points) in ascending order, we could sweep through the components in descending order or we might alternate between ascending and descending orders. The latter procedure is called the symmetric Gauss–Seidel method.
Another effective alternative is to update all the even components first by the expression
and then update all the odd components using
This strategy leads to the red-black Gauss–Seidel method, which is illustrated in following figure for both one-dimensional and two-dimensional grids. Notice that the red points correspond to even-indexed points in one dimension and to points whose index sum is even in two dimensions (assuming that \(i = 0\) and \(j = 0\) corresponds to a boundary). The red points also correspond to what we soon call coarse-grid points.
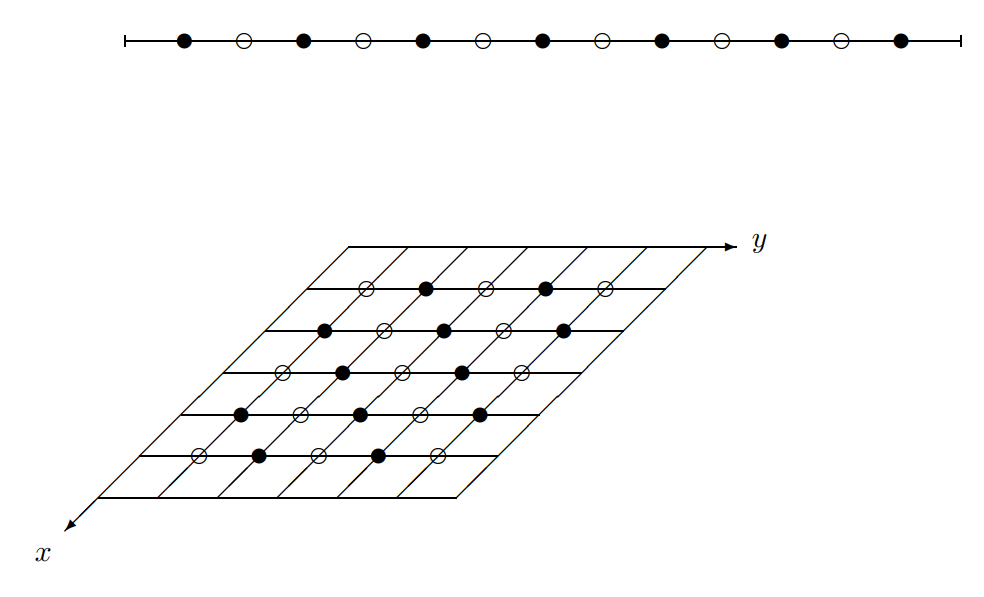
A one-dimensional grid (top) and a two-dimensional grid (bottom), showing the red points (◦) and the black points (•) for red-black relaxation.
The advantages of red-black over regular Gauss–Seidel are not immediately apparent; the issue is often problem-dependent. However, red-black Gauss–Seidel does have a clear advantage in terms of parallel computation. The red points need only the black points for their updating and may therefore be updated in any order. This work represents \(\cfrac{n}{2}\) (or \(\cfrac{n^{2}}{2}\) in two dimensions) independent tasks that can be distributed among several independent processors. In a similar way, the black sweep can also be done by several independent processors. (The Jacobi iteration is also well-suited to parallel computation.)
There are many more basic iterative methods. However, we have seen enough of the essential methods to move ahead toward multigrid. First, it is important to gain some understanding of how these basic iterations perform. We proceed both by analysis and by experimentation.
When studying stationary linear iterations, it is sufficient to work with the homogeneous linear system \(A\mathbf{u}=0\) and use arbitrary initial guesses to start the relaxation scheme. One reason for doing this is that the exact solution is known (\(\mathbf{u}=0\)) and the error in an approximation \(\mathbf{v}\) is simply \(-\mathbf{v}\). Therefore, we return to the one-dimensional model problem with \(\mathbf{f}=0\). It appears as
We obtain some valuable insight by applying various iterations to this system of equations with an initial guess consisting of the vectors (or Fourier modes)
Recall that \(j\) denotes the component (or associated grid point) of the vector \(\mathbf{v}\). The integer \(k\) now makes its first appearance. It is called the wavenumber (or frequency) and it indicates the number of half sine waves that constitute \(\mathbf{v}\) on the domain of the problem. We use \(\mathbf{v}_{k}\) to designate the entire vector \(\mathbf{v}\) with wavenumber \(k\). The following figure illustrates initial guesses \(\mathbf{v}_{1}\), \(\mathbf{v}_{3}\), and \(\mathbf{v}_{6}\). Notice that small values of \(k\) correspond to long, smooth waves, while large values of \(k\) correspond to highly oscillatory waves. We now explore how Fourier modes behave under iteration.
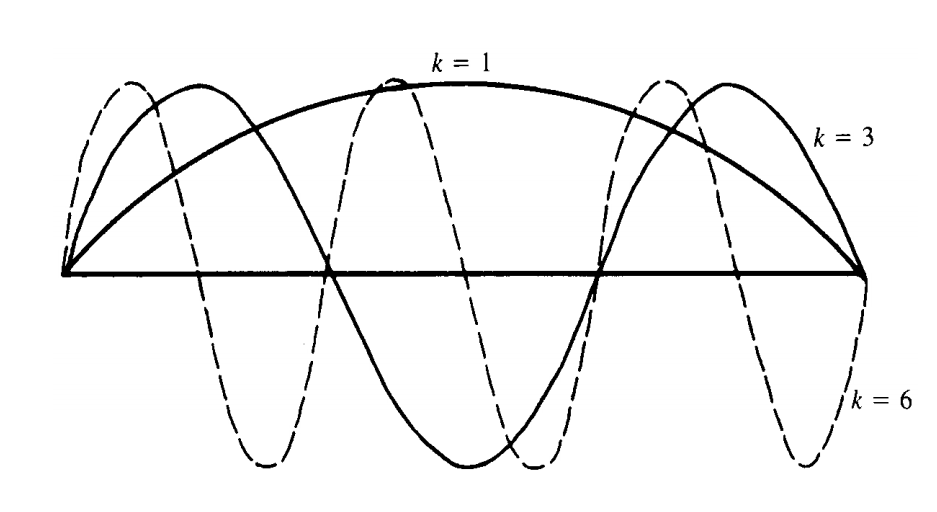
The modes \(v_{j}=\text{sin}\bigg(\cfrac{jk\pi}{n}\bigg)\), \(0 \le j \le n\), with wavenumbers \(k = 1, 3, 61\). The \(k\text{th}\) mode consists of \(\cfrac{k}{2}\) full sine waves on the interval.
We first apply the weighted Jacobi iteration with \(\omega=\cfrac{2}{3}\) to problem (2.3) on a grid with \(n = 64\) points. Beginning with initial guesses of \(\mathbf{v}_{1}\), \(\mathbf{v}_{3}\), and \(\mathbf{v}_{6}\), the iteration is applied 100 times. Recall that the error is just \(-\mathbf{v}\). Figure 2.3(a) shows a plot of the maximum norm of the error versus the iteration number
Let \(\sigma = 0\)
then
where
Let \(\mathbf{f}=0\), then
Gauss–Seidel method
The Gauss–Seidel method incorporates a simple change: components of the new approximation are used as soon as they are computed. This means that components of the approximation vector \(\mathbf{v}\) are overwritten as soon as they are updated. This small change reduces the storage requirement for the approximation vector to only \(n\) locations. The Gauss–Seidel method is also equivalent to successively setting each component of the residual vector to zero and solving for the corresponding component of the solution. When applied to the model problem, this method may be expressed in component form as
With some experimental evidence in hand, we now turn to a more analytical approach. Each of the methods discussed so far may be represented in the form
where \(R\) is one of the iteration matrices derived earlier. Furthermore, all of these methods are designed such that the exact solution, \(\mathbf{u}\), is a fixed point of the iteration. This means that iteration does not change the exact solution:
Subtracting these last two expressions, we find that
Repeating this argument, it follows that after \(m\) relaxation sweeps, the error in the \(m\text{th}\) approximation is given by
Matrix Norms.
Matrix norms can be defined in terms of the commonly used vector norms. Let \(A\) be an \(n\times n\) matrix with elements \(a_{ij}\). Consider the vector norm \(\|\mathbf{x}\|_{p}\) defined by
The matrix norm induced by the vector norm \(\|\cdot\|_{p}\) is defined by
While not obvious without some computation, this definition leads to the following matrix norms induced by the vector norms
Recall that the spectral radius of a matrix is given by
where \(\lambda(A)\) denotes the eigenvalues of \(A\). For symmetric matrices, the matrix \(2-\text{norm}\) is just the spectral radius of \(A\):
If we now choose a particular vector norm and its associated matrix norm, it is possible to bound the error after \(m\) iterations by
This leads us to conclude that if \(\|R\|<1\), then the error is forced to zero as the iteration proceeds. It is shown in many standard texts that
Therefore, it follows that the iteration associated with the matrix \(R\) converges for all initial guesses if and only if \(\rho(R)<1\).
The spectral radius \(\rho(R)\) is also called the asymptotic convergence factor when it appears in the context of iterative methods. It has some useful interpretations. First, it is roughly the worst factor by which the error is reduced with each relaxation sweep. By the following argument, it also tells us approximately how many iterations are required to reduce the error by a factor of \(10^{−d}\). Let \(m\) be the smallest integer that satisfies
This condition will be approximately satisfied if
Solving for \(m\), we have
The quantity − \(\log_{10}[\rho(R)]\) is called the asymptotic convergence rate. Its reciprocal gives the approximate number of iterations required to reduce the error by one decimal digit. We see that as \(\rho(R)\) approaches 1, the convergence rate decreases. Small values of \(\rho(R)\) (that is, \(\rho(R)\) positive and near zero) give a high convergence rate.
Interpreting the Spectral Radius.
The spectral radius is considered to be an asymptotic measure of convergence because it predicts the worst-case error reduction over many iterations. It can be shown that, in any vector norm
Therefore, in terms of error reduction, we have
However, the spectral radius does not, in general, predict the behavior of the error norm for a single iteration. For example, consider the matrix
Clearly, \(\rho(R) = 0\). But if we start with \(\mathbf{e}^{(0)} = (0, 1)^{T}\) and compute \(\mathbf{e}^{(1)}= R\mathbf{e}^{(0)}\), then the convergence factor is
The next iterate achieves the asymptotic estimate, \(\rho(R) = 0\), because \(\mathbf{e}^{(2)}=0\). A better worst-case estimate of error reduction for one or a few iterations is given by the matrix norm \(\|R^{(1)}\|_{2}\). For the above example, we have \(\|R\|_{2}=100\). The discrepancy between the asymptotic convergence factor, \(\rho(R)\), and the worst-case estimate, \(\|R\|_{2}\), disappears when \(R\) is symmetric because then \(\rho(R) = \|R\|_{2}\).
Written in this form, it follows that the eigenvalues of \(R_{\omega}\) and \(A\) are related by
Eigenvalues of the model problem
Compute the eigenvalues of the matrix A of the one-dimensional model problem. (Hint: Write out a typical equation of the system \(A\mathbf{w}=\lambda \mathbf{w}\) with \(w_{0} = w_{n} = 0\). Notice that vectors of the form \(w_{j} = \sin(\cfrac{jk\pi}{n})\) , \(1 \le k \le n − 1, 0 \le j \le n\), satisfy the boundary conditions.) How many distinct eigenvalues are there? Compute \(\lambda_{1}, \lambda_{2}, \lambda_{n−2}, \lambda_{n−1}\), when \(n = 32\).
so that the eigenvalues of \(A\) are
We have established the importance of the spectral radius of the iteration matrix in analyzing the convergence properties of relaxation methods. Now it is time to compute some spectral radii. Consider the weighted Jacobi iteration applied to the one-dimensional model problem. Recalling that \(R_{\omega} = (1 − \omega)I + \omega R_{J}\), we have
Written in this form, it follows that the eigenvalues of \(R_{\omega}\) and \(A\) are related by
The problem becomes one of finding the eigenvalues of the original matrix \(A\). This useful exercise may be done in several different ways. The result is that the eigenvalues of \(A\) are
Also of interest are the corresponding eigenvectors of \(A\). In all that follows, we let \(\omega_{k,j}\) be the \(j\text{th}\) component of the \(k\text{th}\) eigenvector, \(\boldsymbol{\omega}_{k}\). The eigenvectors of \(A\) are then given by
while the eigenvectors of \(R_{\omega}\) are the same as the eigenvectors of \(A\) (Exercise 10). It is important to note that if \(0 < \omega \le 1\), then \(|\lambda_{k}(R_{\omega})| < 1\) and the weighted Jacobi iteration converges. We return to these convergence properties in more detail after a small detour.
The eigenvectors of the matrix A are important in much of the following discussion. They correspond very closely to the eigenfunctions of the continuous model problem. Just as we can expand fairly arbitrary functions using this set of eigenfunctions, it is also possible to expand arbitrary vectors in terms of a set of eigenvectors. Let \(\mathbf{e}^{(0)}\) be the error in an initial guess used in the weighted Jacobi method. Then it is possible to represent \(\mathbf{e}^{(0)}\) using the eigenvectors of \(A\) in the form
where the coefficients \(c_{k}\in \mathbf{R}\) give the “amount” of each mode in the error. We have seen that after \(m\) sweeps of the iteration, the error is given by
Using the eigenvector expansion for \(\mathbf{e}^{(0)}\), we have
The last equality follows because the eigenvectors of \(A\) and \(R_{\omega}\) are the same; therefore, \(R_{\omega}\boldsymbol{\omega}_{k}=\lambda_{k} (R_{\omega})\boldsymbol{\omega}_{k}\).
This expansion for \(\mathbf{e}^{(m)}\) shows that after \(m\) iterations, the \(k\text{th}\) mode of the initial error has been reduced by a factor of \(\lambda_{k} (R_{\omega})\). It should also be noted that the weighted Jacobi method does not mix modes: when applied to a single mode, the iteration can change the amplitude of that mode, but it cannot convert that mode into different modes. In other words, the Fourier modes are also eigenvectors of the iteration matrix. As we will see, this property is not shared by all stationary iterations.
To develop some familiarity with these Fourier modes, Fig. 2.6 shows them on a grid with \(n = 12\) points. Notice that the \(k\text{th}\) mode consists of \(\cfrac{k}{2}\) full sine waves and has a wavelength of \(l=\cfrac{24h}{k}=\cfrac{2}{k}\) (the entire interval has length 1). The \(k=\cfrac{n}{2}\) mode has a wavelength of \(l=4h\) and the \(k = n − 1\) mode has a wavelength of almost \(l=2h\). Waves with wavenumbers greater than \(n\) (wavelengths less than \(2h\)) cannot be represented on the grid. In fact (Exercise 12), through the phenomenon of aliasing, a wave with a wavelength less than \(2h\) actually appears on the grid with a wavelength greater than \(2h\).
At this point, it is important to establish some terminology that is used throughout the remainder of the tutorial. We need some qualitative terms for the various Fourier modes that have been discussed. The modes in the lower half of the spectrum, with wavenumbers in the range \(1 \le k < n2\), are called low-frequency or smooth modes. The modes in the upper half of the spectrum, with \(n2 \le k \le n − 1\), are called high-frequency or oscillatory modes.
Having taken this excursion through Fourier modes, we now return to the analysis of the weighted Jacobi method. We established that the eigenvalues of the iteration matrix are given by
What choice of \(\omega\) gives the best iterative scheme?
Recall that for \(0 < \omega\le 1\), we have \(|\lambda_{k}(R_{\omega})|<1\). We would like to find the value of \(\omega\) that makes \(|\lambda_{k}(R_{\omega})|\) as small as possible for all \(1 \le k \le n − 1\). Figure 2.7 is a plot of the eigenvalues \(\lambda_{k}\) for four different values of \(\omega\). Notice that for all values of \(\omega\) satisfying \(0<\omega\le 1\),
This fact implies that \(\lambda_{1}\), the eigenvalue associated with the smoothest mode, will always be close to 1. Therefore, no value of \(\omega\) will reduce the smooth components of the error effectively. Furthermore, the smaller the grid spacing \(h\), the closer \(\lambda_{1}\) is to 1. Any attempt to improve the accuracy of the solution (by decreasing the grid spacing) will only worsen the convergence of the smooth components of the error. Most basic relaxation schemes share this ironic limitation.
Having accepted the fact that no value of \(\omega\) damps the smooth components satisfactorily, we ask what value of \(\omega\) provides the best damping of the oscillatory components (those with \(n2 \le k \le n − 1\)). We could impose this condition by requiring that
Solving this equation for ω leads to the optimal value \(\omega=\cfrac{2}{3}\).
We also find (Exercise 13) that with \(\omega=\cfrac{2}{3}\), \(|\lambda_{k}| < \cfrac{1}{3}\) for all \(n2 \le k \le n − 1\). This says that the oscillatory components are reduced at least by a factor of three with each relaxation. This damping factor for the oscillatory modes is an important property of any relaxation scheme and is called the smoothing factor of the scheme. An important property of the basic relaxation scheme that underlies much of the power of multigrid methods is that the smoothing factor is not only small, but also independent of the grid spacing \(h\).
We now turn to some numerical experiments to illustrate the analytical results that have just been obtained. Once again, the weighted Jacobi method is applied to the one-dimensional model problem \(A\mathbf{u} = 0\) on a grid with \(n = 64\) points. We use initial guesses (which are also initial errors) consisting of single modes with wavenumbers \(1 \le k \le n − 1\). Figure 2.8 shows how the method performs in terms of different wavenumbers. Specifically, the wavenumber of the initial error is plotted against the number of iterations required to reduce the norm of the initial error by a factor of 100. This experiment is done for weighting factors of \(\omega = 1\) and \(\omega = \cfrac{2}{3}\).
With \(\omega =1\), both the high- and low-frequency components of the error are damped very slowly. Components with wavenumbers near \(n2\) are damped rapidly. This behavior is consistent with the eigenvalue curves of Fig. 2.7. We see a quite different behavior in Fig. 2.8(b) with \(\omega =\cfrac{2}{3}\). Recall that \(\omega =\cfrac{2}{3}\) was chosen to give preferential damping to the oscillatory components. Indeed, the smooth waves are damped very slowly, while the upper half of the spectrum (\(k \ge n2\)) shows rapid convergence. Again, this is consistent with Fig. 2.7.
Another perspective on these convergence properties is provided in Figure 2.9. This time the actual approximations are plotted. The weighted Jacobi method with \(\omega =\cfrac{2}{3}\) is applied to the same model problem on a grid with \(n = 64\) points. Figure 2.9(a) shows the error with wavenumber \(k = 3\) after one relaxation sweep (left plot) and after 10 relaxation sweeps (right plot). This smooth component is damped very slowly. Figure 2.9(b) shows a more oscillatory error (\(k = 16\)) after one and after 10 iterations. The damping is now much more dramatic. Notice also, as mentioned before, that the weighted Jacobi method preserves modes: once a \(k = 3\) mode, always a \(k = 3\) mode.
To develop some familiarity with these Fourier modes, Fig. 2.6 shows them on a grid with \(n = 12\) points. Notice that the \(k\text{th}\) mode consists of \(\cfrac{k}{2}\) full sine waves and has a wavelength of \(l=\cfrac{24h}{k}=\cfrac{2}{k}\) (the entire interval has length 1). The \(k=\cfrac{n}{2}\) mode has a wavelength of \(l=4h\) and the \(k = n − 1\) mode has a wavelength of almost \(l=2h\). Waves with wavenumbers greater than \(n\) (wavelengths less than \(2h\)) cannot be represented on the grid. In fact (Exercise 12), through the phenomenon of aliasing, a wave with a wavelength less than \(2h\) actually appears on the grid with a wavelength greater than \(2h\).
Numerical experiments
Gauss–Seidel iteration matrix
We have belabored the discussion of the weighted Jacobi method because it is easy to analyze and because it shares many properties with other basic relaxation schemes. In much less detail, let us look at the Gauss–Seidel iteration. We can show (Exercise 14) that the Gauss–Seidel iteration matrix for the model problem (matrix \(A\)) has eigenvalues
These eigenvalues, must be interpreted carefully. We see that when \(k\) is close to 1 or \(n\), the corresponding eigenvalues are close to 1 and convergence is slow. However, the eigenvectors of \(R_{G}\) are given by (Exercise 14)
where \(0 \le j \le n\) and \(1 \le k \le n − 1\). These eigenvectors do not coincide with the eigenvectors of \(A\). Therefore, \(\lambda_{k}(R_{G})\) gives the convergence rate, not for the kth mode of \(A\), but for the kth eigenvector of \(R_{G}\).
Gauss–Seidel eigenvalues and eigenvectors.
(a) Show that the eigenvalue problem for the Gauss–Seidel iteration matrix, \(R_{G}\mathbf{w}=\lambda \mathbf{w}\), may be expressed in the form \(U\mathbf{w}=(D − L)\lambda I \mathbf{w}\), where \(U\), \(L\), \(D\) are defined in the text.
(b) Write out the equations of this system and note the boundary condition \(w_{0}=w_{n}=0\). Look for solutions of this system of equations of the form \(w_{j} = \mu_{j}\), where \(\mu \in C\) must be determined. Show that the boundary conditions can be satisfied only if \(\lambda = \lambda_{k} = \cos^{2}\bigg(\cfrac{k\pi}{n}\bigg)\), \(\quad 1\le k \le n-1\).
(c) Show that the eigenvector associated with \(\lambda_{k}\) is \(w_{k,j} = \bigg[\cos\bigg( \cfrac{k\pi}{n}\bigg)\bigg]^{j}\sin\bigg( \cfrac{jk\pi}{n}\bigg)\)
Once again it is useful to express this method in matrix form. Splitting the matrix \(A\) in the form \(A = D − L − U\), we can now write the original system of equations as
or
This representation corresponds to solving the \(j\text{th}\) equation for \(u_j\) and using new approximations for components \(1, 2, \cdots, j − 1\). Defining the Gauss–Seidel iteration matrix by
we can express the method as
Let
then
Basis of Eigenvectors and Principal Vectors Associated with Gauss-Seidel Matrix of A Tridiag [-1 2 -1]