MULTIGRID Continued
MIT Numerical Methods for PDE Lecture 6: Walkthough of a multigrid solver
Fast Methods for Partial Differential and Integral Equations Fall 2017
Elements of Multigrid
Through analysis and experimentation, we have examined some of the basic iterative methods. Our discoveries have formed the beginnings of what we might call a spectral (or Fourier mode) picture of relaxation schemes. As we proceed, more essential details of this picture will become clear. So far we have established that many standard iterative methods possess the smoothing property. This property makes these methods very effective at eliminating the high-frequency or oscillatory components of the error, while leaving the low-frequency or smooth components relatively unchanged. The immediate issue is whether these methods can be modified in some way to make them effective on all error components.
One way to improve a relaxation scheme, at least in its early stages, is to use a good initial guess. A well-known technique for obtaining an improved initial guess is to perform some preliminary iterations on a coarse grid. Relaxation on a coarse grid is less expensive because there are fewer unknowns to be updated. Also, because the convergence factor behaves like \(1 − O(h^{2})\), the coarse grid will have a marginally improved convergence rate. This line of reasoning at least suggests that coarse grids might be worth considering.
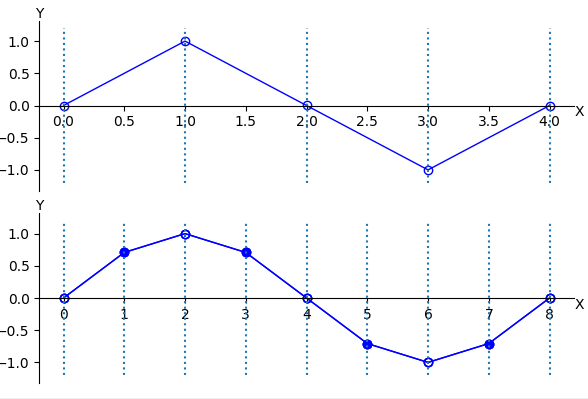
With the coarse grid idea in mind, we can think more carefully about its implications. Recall that most basic relaxation schemes suffer in the presence of smooth components of the error. Assume that a particular relaxation scheme has been applied until only smooth error components remain. We now ask what these smooth components look like on a coarser grid. A smooth wave with \(k = 4\) on a grid Ωh with \(n = 12\) points has been projected directly to the grid \(\Omega^{2h}\) with \(n = 6\) points. On this coarse grid, the original wave still has a wavenumber of \(k = 4\). We see that a smooth wave on \(\Omega^{h}\) looks more oscillatory on \(\Omega^{2h}\).
To be more precise, note that the grid points of the coarse grid \(\Omega^{2h}\) are the even-numbered grid points of the fine grid \(\Omega^{h}\). Consider the \(k\text{th}\) mode on the fine grid evaluated at the even-numbered grid points. If \(1 \le k < \cfrac{n}{2}\), its components may be written as
Notice that superscripts have been used to indicate the grids on which the vectors are defined. From this identity, we see that the \(k\text{th}\) mode on \(\Omega^{h}\) becomes the \(k\text{th}\) mode on \(\Omega^{2h}\); this fact is easier to understand by noting that there are half as many modes on \(\Omega^{2h}\) as there are on \(\Omega^{h}\). The important consequence of this fact is that in passing from the fine grid to the coarse grid, a mode becomes more oscillatory. This is true provided that \(1 \le k < \cfrac{n}{2}\). It should be verified that the \(k = \cfrac{n}{2}\) mode on \(\Omega^{h}\) becomes the zero vector on \(\Omega^{2h}\).
As an aside, it is worth mentioning that fine-grid modes with \(k > \cfrac{n}{2}\) undergo a more curious transformation. Through the phenomenon of aliasing mentioned earlier, the kth mode on \(\Omega^{h}\) becomes the (n − k)th mode on \(\Omega^{2h}\) when \(k > \cfrac{n}{2}\). In other words, the oscillatory modes of \(\Omega^{h}\) are misrepresented as relatively smooth modes on \(\Omega^{2h}\).
The important point is that smooth modes on a fine grid look less smooth on a coarse grid. This suggests that when relaxation begins to stall, signaling the predominance of smooth error modes, it is advisable to move to a coarser grid; there, the smooth error modes appear more oscillatory and relaxation will be more effective. The question is: how do we move to a coarser grid and relax on the more oscillatory error modes?
It is at this point that multigrid begins to come together like a jigsaw puzzle. We must keep all of the related facts in mind. Recall that we have an equation for the error itself, namely, the residual equation. If \(\mathbf{v}\) is an approximation to the exact solution \(\mathbf{u}\), then the error \(\mathbf{e}=\mathbf{u}-\mathbf{v}\) satisfies
which says that we can relax directly on the error by using the residual equation. There is another argument that justifies the use of the residual equation:
Relaxation on the original equation \(A\mathbf{u}=\mathbf{f}\) with an arbitrary initial guess \(\mathbf{v}\) is equivalent to relaxing on the residual equation \(A\mathbf{e}=\mathbf{r}\) with the specific initial guess \(\mathbf{e}=0\).
This intimate connection between the original and the residual equations further motivates the use of the residual equation.
We must now gather these loosely connected ideas. We know that many relaxation schemes possess the smoothing property. This leads us to consider using coarser grids during the computation to focus the relaxation on the oscillatory components of the error. In addition, there seems to be good reason to involve the residual equation in the picture. We now try to give these ideas a little more definition by proposing two strategies.
We begin by proposing a strategy that uses coarse grids to obtain better initial guesses.
Relax on \(A\mathbf{u}=\mathbf{f}\) on a very coarse grid to obtain an initial guess for the next finer grid.
…
Relax on \(A\mathbf{u}=\mathbf{f}\) on \(\Omega^{4h}\) to obtain an initial guess for \(\Omega^{2h}\).
Relax on \(A\mathbf{u}=\mathbf{f}\) on \(\Omega^{2h}\) to obtain an initial guess for \(\Omega^{h}\).
Relax on \(A\mathbf{u}=\mathbf{f}\) on \(\Omega^{h}\) to obtain a final approximation to the solution.
This idea of using coarser grids to generate improved initial guesses is the basis of a strategy called nested iteration. Although the approach is attractive, it also leaves some questions. For instance, what does it mean to relax on \(A\mathbf{u}=\mathbf{f}\) on \(\Omega^{2h}\)? We must somehow define the original problem on the coarser grids. Also, what happens if, having once reached the fine grid, there are still smooth components in the error? We may have obtained some improvement by using the coarse grids, but the final iteration will stall if smooth components still remain. We return to these questions and find answers that will allow us to use nested iteration in a very powerful way.
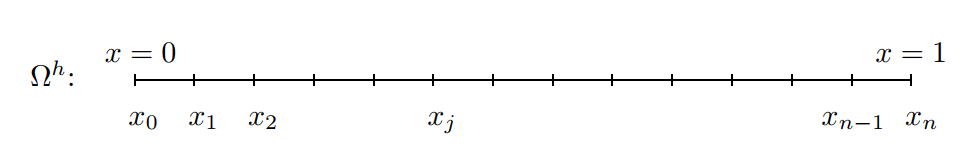
One-dimensional grid on the interval \(0\le x\le 1\). The grid spacing is \(h=\cfrac{1}{n}\) and the \(j\text{th}\) grid point is \(x_{j} = jh\quad\) for \(\quad 0\le j\le n\).
This idea of using coarser grids to generate improved initial guesses is the basis of a strategy called nested iteration. Although the approach is attractive, it also leaves some questions. For instance, what does it mean to relax on \(A\mathbf{u} = \mathbf{f}\) on \(\Omega^{2h}\)? We must somehow define the original problem on the coarser grids. Also, what happens if, having once reached the fine grid, there are still smooth components in the error? We may have obtained some improvement by using the coarse grids, but the final iteration will stall if smooth components still remain. We return to these questions and find answers that will allow us to use nested iteration in a very powerful way.
A second strategy incorporates the idea of using the residual equation to relax on the error. It can be represented by the following procedure:
Relax on \(A\mathbf{u} = \mathbf{f}\) on \(\Omega^{h}\) to obtain an approximation \(\mathbf{v}^{h}\).
Compute the residual \(\mathbf{r}=\mathbf{f}-A\mathbf{v}^{h}\). Relax on the residual equation \(A\mathbf{e} = \mathbf{r}\) on \(\Omega^{2h}\) to obtain an approximation to the error \(\mathbf{e}^{2h}\).
Correct the approximation obtained on \(\Omega^{h}\) with the error estimate obtained on \(\Omega^{2h} : \mathbf{v}^{h} \leftarrow \mathbf{v}^{h} + \mathbf{e}^{2h}\).
This procedure is the basis of what is called the correction scheme. Having relaxed on the fine grid until convergence deteriorates, we relax on the residual equation on a coarser grid to obtain an approximation to the error itself. We then return to the fine grid to correct the approximation first obtained there.
There is a rationale for using this correction strategy, but it also leaves some questions to be answered. For instance, what does it mean to relax on \(A\mathbf{e} = \mathbf{r}\) on \(\Omega^{2h}\)? To answer this question, we first need to know how to compute the residual on \(\Omega^{h}\) and transfer it to \(\Omega^{2h}\). We also need to know how to relax on \(\Omega^{2h}\) and what initial guess should be used. Moreover, how do we transfer the error estimate from \(\Omega^{2h}\) back to \(\Omega^{h}\)? These questions suggest that we need mechanisms for transferring information between the grids. We now turn to this important consideration.
In our discussion of intergrid transfers, we consider only the case in which the coarse grid has twice the grid spacing of the next finest grid. This is a nearly universal practice, because there is usually no advantage in using grid spacings with ratios other than 2. Think for a moment about the step in the correction scheme that requires transferring the error approximation \(\mathbf{e}^{2h}\) from the coarse grid \(\Omega^{2h}\) to the fine grid \(\Omega^{h}\). This is a common procedure in numerical analysis and is generally called interpolation or prolongation. Many interpolation methods could be used. Fortunately, for most multigrid purposes, the simplest of these is quite effective. For this reason, we consider only linear interpolation.
The linear interpolation operator will be denoted \(I_{2h}^{h}\). It takes coarse-grid vectors and produces fine-grid vectors according to the rule \(I_{2h}^{h}\mathbf{v}^{2h}=\mathbf{v}^{h}\), where
At even-numbered fine-grid points, the values of the vector are transferred directly from \(\Omega^{2h}\) to \(\Omega^{h}\). At odd-numbered fine-grid points, the value of \(\mathbf{v}^{h}\) is the average of the adjacent coarse-grid values.
In anticipation of discussions to come, we note that \(I_{2h}^{h}\) is a linear operator from \(\mathbf{R}^{\cfrac{n}{2}-1}\) to \(\mathbf{R}^{n-1}\). It has full rank and the trivial null space, \(\mathcal{N} = {0}\). For the case n = 8, this operator has the form
How well does this interpolation process work? First assume that the “real” error (which is not known exactly) is a smooth vector on the fine grid. Assume also that a coarse-grid approximation to the error has been determined on \(\Omega^{2h}\) and that this approximation is exact at the coarse-grid points. When this coarsegrid approximation is interpolated to the fine grid, the interpolant is also smooth. Therefore, we expect a relatively good approximation to the fine-grid error. By contrast, if the “real” error is oscillatory, even a very good coarse-grid approximation may produce an interpolant that is not very accurate.
We now have a well-defined way to transfer vectors between fine and coarse grids. Therefore, we can return to the correction scheme and make it precise. To do this, we define the following two-grid correction scheme.
Two-Grid Correction Scheme
Relex \(\nu_{1}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
Compute the fine-grid residual \(\mathbf{r}^{h}=\mathbf{f}^{h}-A^{h}\mathbf{v}^{h}\) and restrict it to the coarse grid by \(\mathbf{r}^{2h}=I_{h}^{2h}\mathbf{r}^{h}\)
Solve \(A^{2h}\mathbf{e}^{2h}=\mathbf{r}^{2h}\) on \(\Omega^{2h}\).
Interpolate the coarse-grid error to the fine grid by \(\mathbf{e}^{h}=I_{2h}^{h}\mathbf{e}^{2h}\) and correct the fine-grid approximation by \(\mathbf{v}^{h}\leftarrow\mathbf{v}^{h}+\mathbf{e}^{h}\)
Relex \(\nu_{2}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
This procedure is simply the original correction scheme, now refined by the use of the intergrid transfer operators. We relax on the fine grid until it ceases to be worthwhile; in practice, \(\nu_{1}\) is often 1, 2, or 3. The residual of the current approximation is computed on \(\Omega^{h}\) and then transferred by a restriction operator to the coarse grid. As it stands, the procedure calls for the exact solution of the residual equation on \(\Omega^{2h}\), which may not be possible. However, if the coarse-grid error can at least be approximated, it is then interpolated up to the fine grid, where it is used to correct the fine-grid approximation. This is followed by \(\nu_{2}\) additional fine-grid relaxation sweeps.
Several comments are in order. First, notice that the superscripts \(h\) or \(2h\) are essential to indicate the grid on which a particular vector or matrix is defined. Second, all of the quantities in the above procedure are well defined except for \(A^{2h}\). For the moment, we take \(A^{2h}\) simply to be the result of discretizing the problem on \(\Omega^{2h}\). Finally, the integers \(\nu_{1}\) and \(\nu_{2}\) are parameters in the scheme that control the number of relaxation sweeps before and after visiting the coarse grid. They are usually fixed at the start, based on either theoretical considerations or on past experimental results.
It is important to appreciate the complementarity at work in the process. Relaxation on the fine grid eliminates the oscillatory components of the error, leaving a relatively smooth error. Assuming the residual equation can be solved accurately on \(\Omega^{2h}\), it is still important to transfer the error accurately back to the fine grid. Because the error is smooth, interpolation should work very well and the correction of the fine-grid solution should be effective.
Numerical example.
A numerical example will be helpful. Consider the weighted Jacobi method with \(\omega=\cfrac{2}{3}\) applied to the one-dimensional model problem \(A\mathbf{u}=0\) on a grid with \(n = 64\) points. We use an initial guess,
consisting of the \(k = 16\) and \(k = 40\) modes. The following two-grid correction scheme is used:
Relex three times on \(A^{h}\mathbf{u}^{h}=0\) on \(\Omega^{h}\) with initial \(\mathbf{v}^{h}\).
Compute \(\mathbf{r}^{2h}=I_{h}^{2h}\mathbf{r}^{h}\).
Relex three times on \(A^{2h}\mathbf{e}^{2h}=\mathbf{r}^{2h}\) on \(\Omega^{2h}\) with initial guess \(\mathbf{e}^{2h}=0\)
Correct the fine-grid approximation: \(\mathbf{v}^{h}\leftarrow\mathbf{v}^{h}+I_{2h}^{h}\mathbf{e}^{2h}\).
Relex three times on \(A^{h}\mathbf{u}^{h}=0\) on \(\Omega^{h}\) with initial \(\mathbf{v}^{h}\).
Let \(\mathbf{f}=0\), then
Relex \(\nu_{1}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
Compute the fine-grid residual \(\mathbf{r}^{h}=\mathbf{f}^{h}-A^{h}\mathbf{v}^{h}=-A^{h}\mathbf{v}^{h}\) and restrict it to the coarse grid by \(\mathbf{r}^{2h}=I_{h}^{2h}\mathbf{r}^{h}\)
Solve \(A^{2h}\mathbf{e}^{2h}=\mathbf{r}^{2h}\) on \(\Omega^{2h}\).
Interpolate the coarse-grid error to the fine grid by \(\mathbf{e}^{h}=I_{2h}^{h}\mathbf{e}^{2h}\) and correct the fine-grid approximation by \(\mathbf{v}^{h}\leftarrow\mathbf{v}^{h}+\mathbf{e}^{h}\)
Relex \(\nu_{2}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
Let \(n=8\), then
The second class of intergrid transfer operations involves moving vectors from a fine grid to a coarse grid. They are generally called restriction operators and are denoted by \(I_{h}^{2h}\). The most obvious restriction operator is injection. It is defined by \(I_{h}^{2h}\mathbf{v}^{h}=\mathbf{v}^{2h}\), where
The two-grid correction scheme, as outlined above, leaves one looming procedural question: what is the best way to solve the coarse-grid problem \(A^{2h}\mathbf{e}^{2h}=\mathbf{r}^{2h}\)? The answer may be apparent, particularly to those who think recursively. The coarse-grid problem is not much different from the original problem. Therefore, we can apply the two-grid correction scheme to the residual equation on \(Ω^{2h}\), which means relaxing there and then moving to \(Ω^{4h}\) for the correction step. We can repeat this process on successively coarser grids until a direct solution of the residual equation is possible.
To facilitate the description of this procedure, some economy of notation is desirable. The same notation is used for the computer implementation of the resulting algorithm. We call the right-side vector of the residual equation \(\mathbf{f}^{2h}\), rather than \(\mathbf{r}^{2h}\), because it is just another right-side vector. Instead of calling the solution of the residual equation \(\mathbf{e}^{2h}\), we use \(\mathbf{u}^{2h}\) because it is just a solution vector. We can then use \(\mathbf{v}^{2h}\) to denote approximations to \(\mathbf{u}^{2h}\). These changes simplify the notation, but it is still important to remember the meaning of these variables. One more point needs to be addressed: what initial guess do we use for \(\mathbf{v}^{2h}\) on the first visit to \(Ω^{2h}\)? Because there is presumably no information available about the solution, \(\mathbf{u}^{2h}\), we simply choose \(\mathbf{v}^{2h}=0\). Here then is the two-grid correction scheme, now imbedded within itself. We assume that there are \(l > 1\) grids with grid spacings \(h, 2h, 4h, . . . , Lh = 2^{l-1}h\).
V-Cycle Scheme
Relex \(\nu_{1}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
- Compute the fine-grid residual \(\mathbf{r}^{h}=\mathbf{f}^{h}-A^{h}\mathbf{v}^{h}\) and restrict it to the coarse grid by \(\mathbf{r}^{2h}=I_{h}^{2h}\mathbf{r}^{h}\)
Relax on \(A^{2h}\mathbf{u}^{2h}=\mathbf{f}^{2h}\) \(\nu_{1}\) times with initial guess \(\mathbf{v}^{2h}=0\) ( \(A^{2h}\mathbf{e}^{2h}=\mathbf{r}^{2h}\) )
Relax on \(A^{2h}\mathbf{u}^{2h}=\mathbf{f}^{2h}\) \(\nu_{2}\) times with initial guess \(\mathbf{v}^{2h}\)
Correct the fine-grid approximation \(\mathbf{v}^{h}\leftarrow\mathbf{v}^{h}+I_{2h}^{h}\mathbf{e}^{2h}\)
Relex \(\nu_{2}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
V-Cycle Scheme (Recursive Definition)
Relex \(\nu_{1}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
If \(\Omega^{h}\) = coarsest grid, then go to step 4.
Else
Correct \(\mathbf{v}^{h}\leftarrow v^{h}+I_{2h}^{h}\mathbf{v}^{2h}\).
Relax \(\nu_{2}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) with initial guess \(\mathbf{v}^{h}\).
The V-cycle is just one of a family of multigrid cycling schemes. The entire family is called the µ-cycle method and is defined recursively by the following.
µ-Cycle Scheme
Relex \(\nu_{1}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) on \(\Omega^{h}\) with initial guess \(\mathbf{v}^{h}\).
If \(\Omega^{h}\) = coarsest grid, then go to step 4.
Else
Correct \(\mathbf{v}^{h}\leftarrow v^{h}+I_{2h}^{h}\mathbf{v}^{2h}\).
Relax \(\nu_{2}\) times on \(A^{h}\mathbf{u}^{h}=\mathbf{f}^{h}\) with initial guess \(\mathbf{v}^{h}\).
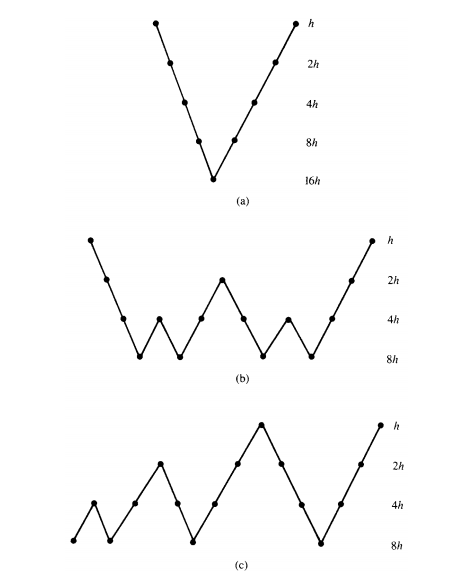
Schedule of grids for (a) V-cycle, (b) W-cycle, and (c) FMG scheme, all on four levels.
In practice, only \(\mu=1\) (which gives the V-cycle) and \(\mu=2\) are used. The above figure shows the schedule of grids for \(\mu=2\) and the resulting W-cycle. We refer to a V-cycle with \(\nu_{1}\) relaxation sweeps before the correction step and \(\nu_{2}\) relaxation sweeps after the correction step as a \(V(\nu_{1},\nu_{2})\)-cycle, with a similar notation for W-cycles.
We originally stated that two ideas would lead to multigrid. So far we have developed only the correction scheme. The nested iteration idea has yet to be explored. Recall that nested iteration uses coarse grids to obtain improved initial guesses for fine-grid problems. In looking at the V-cycle, we might ask how to obtain an informed initial guess for the first fine-grid relaxation. Nested iteration would suggest solving a problem on \(\Omega^{2h}\). But how can we obtain a good initial guess for the \(\Omega^{2h}\) problem? Nested iteration sends us to \(\Omega^{4h}\). Clearly, we are on another recursive path that leads to the coarsest grid. The algorithm that joins nested iteration with the V-cycle is called the full multigrid V-cycle (FMG) . Given first in explicit terms, it appears as follows.
We initialize the coarse-grid right sides by transferring \(\mathbf{f}^{h}\) from the fine grid. Another option is to use the original right-side function \(\mathbf{f}\). The cycling parameter, \(\nu_{0}\), sets the number of V-cycles done at each level. It is generally determined by a previous numerical experiment; \(\nu_{0}=1\) is the most common choice. Expressed recursively, the algorithm has the following compact form.
Full Multigrid V-Cycle (Recursive Form)
If \(\Omega^{h}\) = coarsest grid, set \(\mathbf{v}^{h}\leftarrow 0\) and go to step 3.
Else
Correct \(\mathbf{v}^{h}\leftarrow \mathbf{v}^{h}+I_{2h}^{h}\mathbf{v}^{2h}\).
\(\mathbf{v}^{h}\leftarrow V^{h}(\mathbf{v}^{h},\mathbf{f}^{h})\) \(\nu_{0}\) times.
Full Multigrid V-Cycle
Compute residual
Restrict residual
Solve Error Equation
Correct result